机器监控
对于监控系统,基础功能的强弱确实非常关键,但是如何在不同的场景落地实践,则更为关键。在《监控实践》章节,搜罗各类监控实践经验,会以不同的组件分门别类,您如果对某个组件有好的实践经验,欢迎提 PR,把您的文章链接附到对应的组件目录下。
FAQ
我的机器列表里可以看到机器,也可以看到机器的CPU、内存等信息,为什么仪表盘查不到数据?
💡 注意:机器列表里那些 CPU、内存等信息,不是存储在时序库的,而是存储在 Redis 中的,是 Categraf 调用夜莺的 heartbeat 接口时上报上来的,和 Remote write 走的是两个路径。
这个问题从如下几个方面排查:
1、看 Categraf 的日志
作为 IT 从业人员,第一反应就是应该看相关组件的日志,Categraf 的日志默认打在 stdout,如果是 systemd 托管的 Categraf,则使用 journalctl 查看,比如 journalctl -u categraf.service。如果对 Linux 不太熟悉,直接在命令行里前台启动 Categraf,可以更方便查看日志,即:
./categraf
如上就是直接把 Categraf 进程启动在前台,日志会直接输出到终端,方便查看。
2、确认 Categraf 的配置
机器列表里可以正常看到内容,说明 Categraf 的配置里的 heartbeat 部分配置是正常的。仪表盘看不到监控数据,可能是 writer 部分的配置有问题,writer 部分的 url 应该配置为夜莺的地址,urlpath 是 /prometheus/v1/write。
3、确认夜莺的配置
Categraf 把数据推给夜莺,夜莺不直接存储数据,而是转发给 TSDB,TSDB 可以是 Prometheus 或者 VictoriaMetrics 等,夜莺把数据发给哪些 TSDB?是由夜莺的配置文件 config.toml 中的 Pushgw.Writers 来决定的。
需要确保 Pushgw.Writers 中的配置是正确的,且夜莺的 n9e 进程可以正常访问到这些 TSDB。
4、查夜莺的日志
如果数据转发给时序库失败,夜莺的日志会有相关提示,查看夜莺的日志可以帮助定位问题。社区里新手用户常见的错误是夜莺写数据给 Prometheus,但是 Prometheus 的启动参数有问题,没有开启 remote write 接口,导致夜莺写数据失败。这类错误通常会在夜莺的日志中有提示,可以直接看到应该给 Prometheus 增加什么参数,照着修改即可。
5、时间校准
比如本地笔记本电脑的时间和服务端的时间是否一致,监控系统对时间是很敏感的。如果时间没有校准,可能会导致数据无法正常展示。
6、查看仪表盘的配置
有些仪表盘是查看时序库里的所有数据,有些仪表盘是只能查看所属业务组下面的机器的监控数据(通过仪表盘变量控制的),如果是后者类型的仪表盘,就需要确保业务组下面有机器。
可否把监控数据写到 TDEngine 等其他时序库?
首先,你需要了解 Prometheus remote write 协议(可以问问 Google 或 GPT)。Categraf 采集的数据是通过 Prometheus remote write 协议推送给夜莺的,夜莺也是通过 Prometheus remote write 协议把数据转发给时序库的。
所以,如果某个时序库支持接收 Prometheus remote write 协议的数据,那么就可以接入 Categraf 或夜莺。这个信息从哪里得到?去看(或搜)时序库的文档,如果它支持接收 Prometheus remote write 协议的数据,那么它大概率会在文档里提及。如果它的文档里没有写,大概率就是不支持或支持的不好不推荐使用。
机器失联监控怎么做?
在 Prometheus 里,每台机器部署 Node-Exporter,Prometheus 主动去抓取 Node-Exporter 的数据,这种方式叫做PULL。这种方式的好处是,Prometheus 可以知道机器是否失联,因为如果机器失联,Prometheus 就无法抓取到数据。抓取成功的话,会有个 up 指标,值为 1;如果抓取失败,则 up 指标的值为 0。
所以,在 Prometheus PULL 模式下,可以使用 up 指标来监控机器是否失联。
夜莺默认使用 Categraf 采集机器的监控数据,Categraf 不暴露 /metrics 接口,而是通过 remote write 协议把数据推给夜莺,这种模式称为PUSH。在这种模式下,不会有 up 指标,那如何监控机器是否失联呢?
夜莺的告警规则里,提供了一个 Host 类型的告警规则,可以配置失联告警:
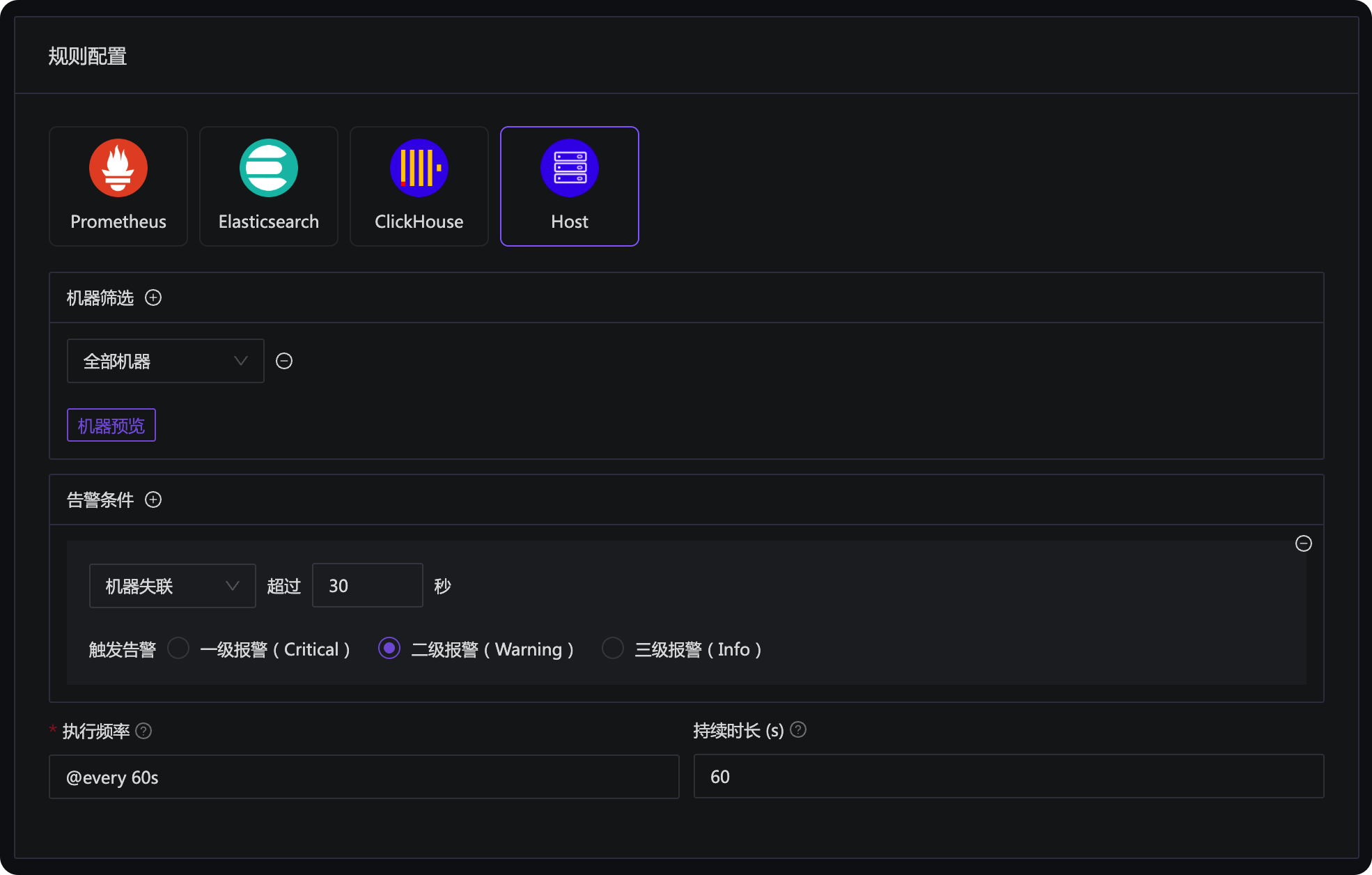
通常配置为对所有机器生效即可,如果你有一些特殊的机器,不想做失联告警,可以把这些机器放到特殊的业务组或者打上特殊的标签,然后在机器筛选这里,给过滤掉。
或者使用 PING 监控对机器发起 PING 探测,然后对 PING 的探测结果配置告警规则,也是可以的。有很多监控工具都支持 PING 探测,比如 Telegraf、Categraf、Blackbox Exporter 等。