夜莺架构设计
夜莺的架构比较简单,如果只是测试功能,一个二进制就可以启动,如果要上到生产环境,则要依赖 MySQL 和 Redis。有些公司会有多个机房,有些边缘机房和中心机房的网络质量较差,夜莺也针对这种情况做了专门的设计。
架构图
不考虑边缘模式的话,夜莺只有一个主进程,即 n9e 进程,依赖 MySQL 和 Redis 存储一些管理数据,可以接入多种数据源,技术架构图示意如下:
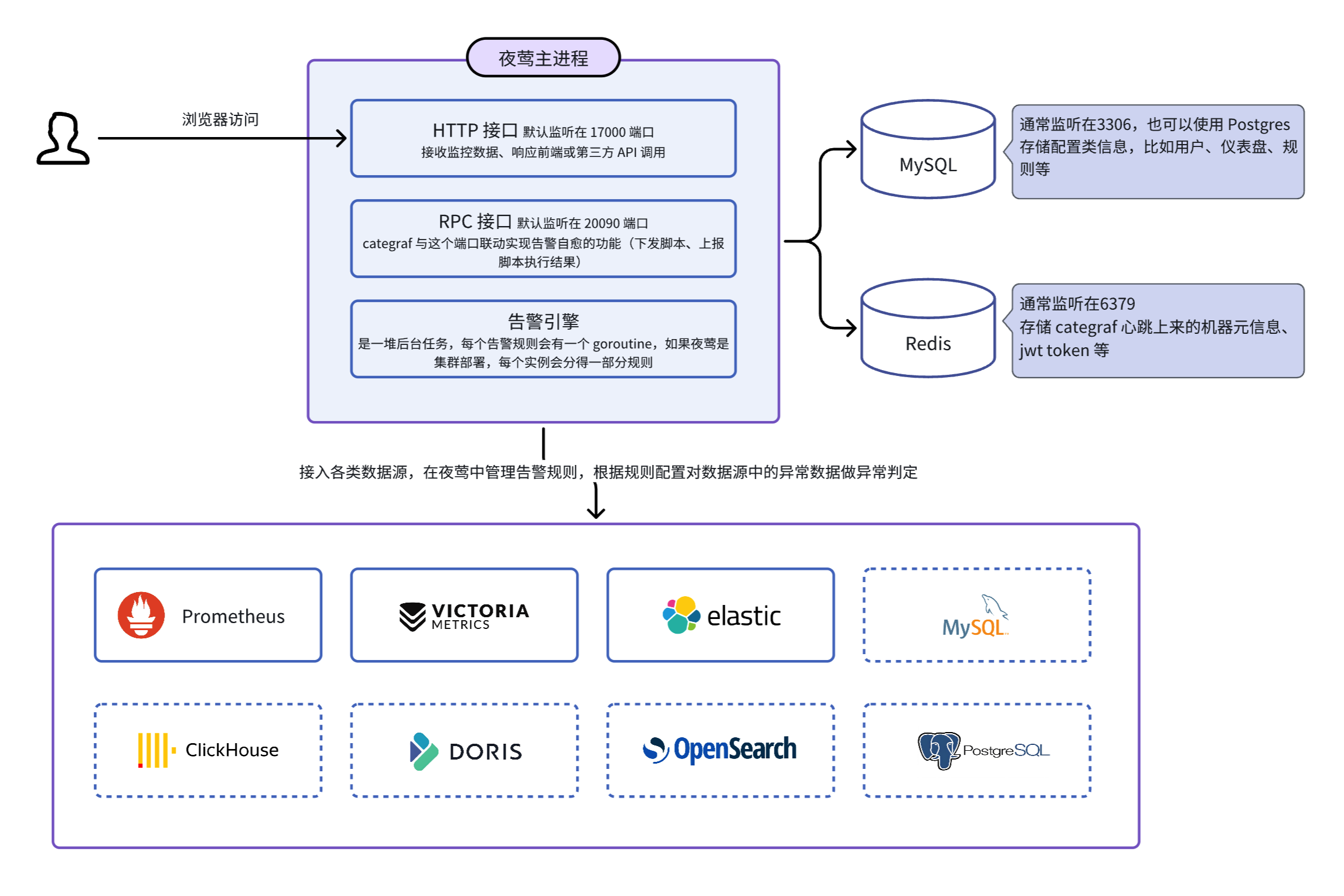
初期支持的数据源:Prometheus、VictoriaMetrics、ElasticSearch,既支持看图也支持告警,后面夜莺侧重在做告警引擎,所以后面新支持的数据源就只支持告警。
根据监控数据是否流经夜莺,可以分成两个模式:
- 模式1:监控数据不流经夜莺,用户自己搞定数据采集的问题,仅把时序库配置到夜莺里,使用夜莺看图和配置告警。上面的架构图就是典型的这种模式。
- 模式2:数据流经夜莺,Categraf 通过 remote write 协议把数据推给夜莺,夜莺不直接存储数据,而是把数据转存到时序库,转存到哪些时序库?由夜莺配置文件 config.toml 中的
Pushgw.Writers来决定,模式2下的架构图如下:
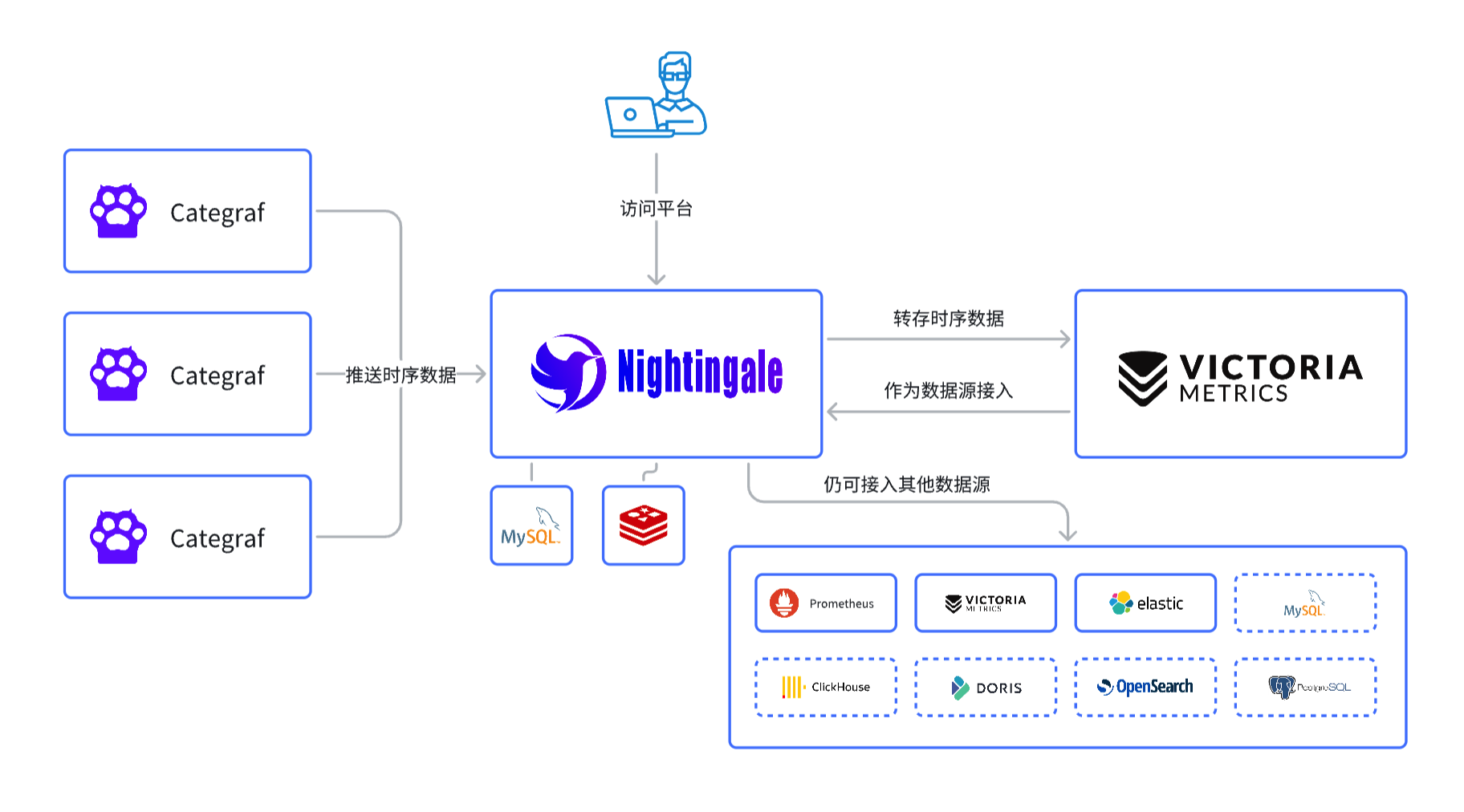
上图中,夜莺接到监控数据之后转发给了 VictoriaMetrics,当然,也可以转发给 Prometheus,如果要转发给 Prometheus,记得 Prometheus 启动的时候要打开 remote receiver 的功能(./prometheus --help | grep receiver 可以看到具体是要加哪个控制参数),即开启 Prometheus 的 /api/v1/write 接口。
🟢 如果是新用户,建议直接使用 VictoriaMetrics,VictoriaMetrics 性能更好,且支持集群模式,而且,和 Prometheus 接口兼容。不过 VictoriaMetrics 的中文资料比 Prometheus 更少一些。
单节点测试模式
从夜莺的 github releases 下载发布包,解压之后里边有个 n9e 二进制文件,直接 ./n9e 就可以运行起来,默认端口是 17000,默认用户名是 root,密码是 root.2020。
n9e 进程只依赖二进制同级目录的 etc 和 integrations 目录,不依赖其他任何服务。
在这种单机模式下,方便做快速测试,不过不建议用于生产环境。此种模式下,夜莺会把配置类数据(比如用户信息、告警规则、仪表盘等)存储在本地的 SQLite 数据库文件中,所以 n9e 进程启动之后,同级目录下会生成一个 n9e.db 的 SQLite 数据库文件。
单节点生产模式
如果要上到生产环境,则需要依赖 MySQL 和 Redis。所以,需要在配置文件 etc/config.toml 中配置 MySQL 和 Redis 的连接信息。
MySQL 的关键配置样例:
[DB]
DBType = "mysql"
DSN = "root:YourPa55word@tcp(localhost:3306)/n9e_v6?charset=utf8mb4&parseTime=True&loc=Local"
上面 DSN(连接字符串)的格式是 用户名:密码@tcp(地址:端口)/数据库名?参数,其中 n9e_v6 是夜莺的数据库名,从 V6 版本开始,就一直习惯使用这个名字了(即便现在是 V8+ 版本了),建表语句里也一直延用了这个名字。
Redis 的关键配置样例:
[Redis]
Address = "127.0.0.1:6379"
RedisType = "standalone"
上面只是给了最基础的配置样例,配置文件中还有很多其他配置项,具体可以参考配置文件中的注释,也可以参考这里的配置文件说明。
夜莺集群
集群模式很简单,只需要搞多台机器,每台机器都部署 n9e 进程(进程要想正常工作依赖 etc 和 integrations 目录),多个 n9e 的配置文件确保完全一致,共享同一套 MySQL 和 Redis,即可。
多个 n9e 进程会自动分派告警规则,比如有 2 个 n9e 进程,用户共配置了 100 条告警规则,夜莺会自动把这 100 条告警规则分配到 2 个 n9e 进程上,每个进程大概 50 条告警规则(一个规则只会在某一个 n9e 实例上运行,不会重复告警)。如果某个机器挂了,另一个机器上的 n9e 会接管它的告警规则,继续工作。
边缘模式
上面讲到的几种模式,都是中心化模式,但实际生产环境里,可能会有多个机房,中心机房和边缘机房的网络质量可能不太好,如果让中心机房的 n9e 负责边缘机房的某个时序库的告警,会不稳定,有时甚至 n9e 直接连不通边缘机房的时序库,这时就需要夜莺的边缘机房下沉部署模式。
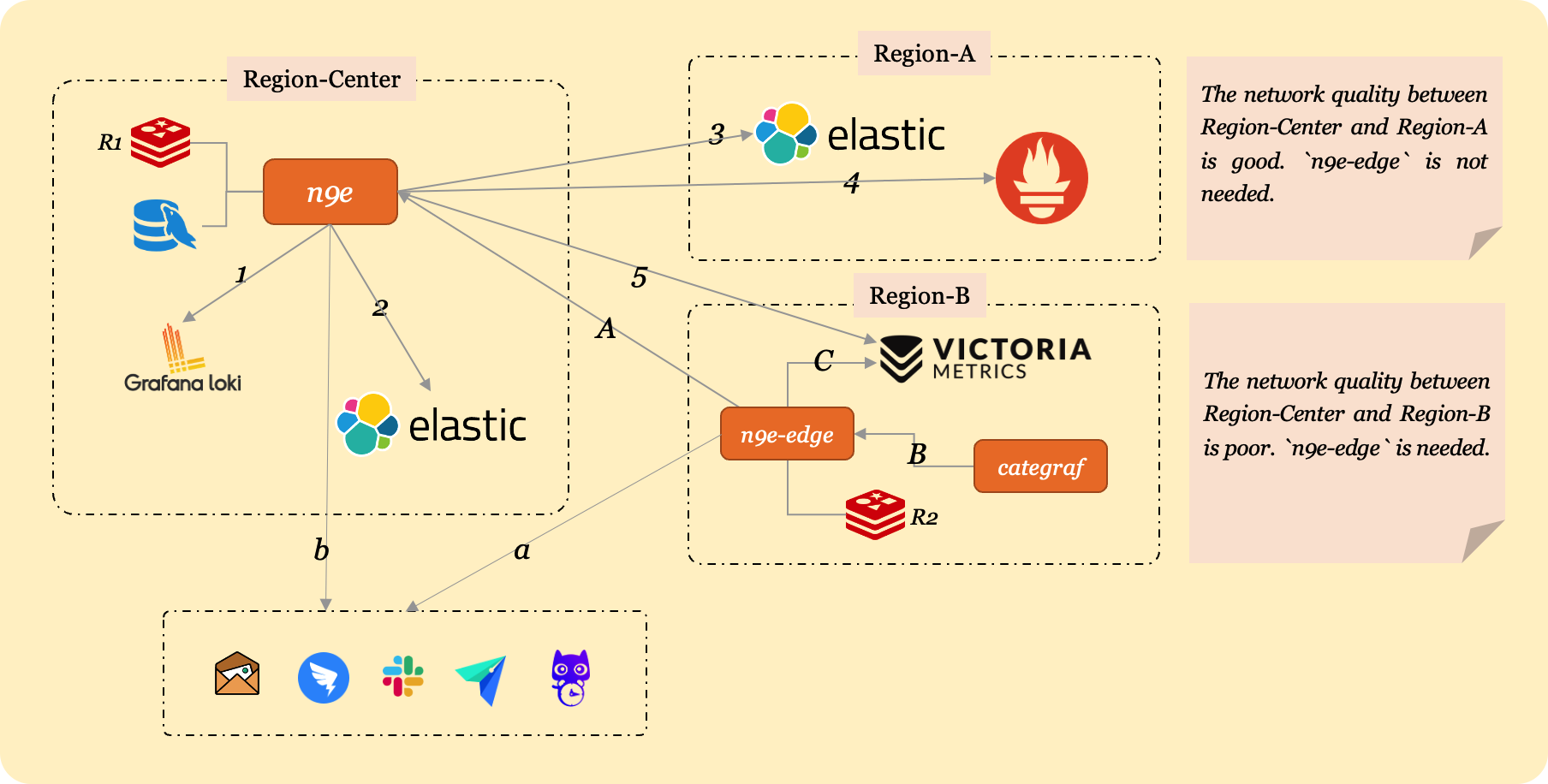
我们这里假设贵司有 3 个机房:中心主力机房、边缘机房 A 和边缘机房 B,其中边缘机房 A 和中心机房之间有专线,网络链路很好,边缘机房 B 和中心机房之间没有专线,走公网,网络链路不够可靠。
n9e 进程部署在中心主力机房,n9e 依赖 mysql 和 redis,所以 mysql 和 redis 也部署在中心主力机房。如果你想做高可用,中心机房的 n9e 可以部署多个实例,配置文件保持一致,连同一个 mysql 和 redis 即可。
上图中,我们有 5 个数据源:
- 中心机房有一套 Loki,一套 ElasticSearch
- 边缘机房 A 有一套 ElasticSearch,一套 Prometheus
- 边缘机房 B 有一套 VictoriaMetrics
我们希望在中心 n9e 统一查看这 5 个数据源的数据,所以要把这 5 个数据源的访问地址配置到夜莺中,菜单位置:集成中心-数据源。
中心 n9e 可以通过内网地址直接连通中心机房和边缘机房 A 的数据源,但是无法直接连通边缘机房 B 的数据源(因为没有专线),那只能把边缘机房 B 的 VictoriaMetrics 暴露一个公网地址出来,中心 n9e 通过公网地址访问边缘机房 B 的 VictoriaMetrics,即:
- 机房 B 的 VictoriaMetrics 暴露公网访问地址,比如为:https://ex.a.com
- 在夜莺的 WEBUI 上配置数据源时,把机房 B 的 VictoriaMetrics 的 URL 配置为:https://ex.a.com
架构图中的 1、2、3、4、5 这 5 条线,表示中心 n9e 和 5 个数据源的连接关系。用户在查询数据的时候,是在 n9e 的 web 上查的,发请求给 n9e 进程,n9e 进程此时相当于一个 proxy,把请求代理给后端的各个数据源,然后把数据源的数据返回给用户。
n9e-edge 部署在边缘机房 B,用于处理 B 机房 VictoriaMetrics 的告警判定,n9e-edge 会从中心 n9e 同步告警规则(即图中的 A 那条线),然后把告警规则缓存在内存里,对本机房的 VictoriaMetrics 做告警判定工作。这样的架构下,n9e-edge 和 VictoriaMetrics 是内网连通的,所以告警比较可靠,另外即便 n9e-edge 连不通中心机房的 n9e 了,也不影响 B 机房的告警判定工作,因为 n9e-edge 内存中已经缓存了告警规则。
n9e-edge 产生的告警事件会调用 n9e 的接口写回中心 mysql,调用钉钉、飞书、FlashDuty 等的接口发送通知。如果 n9e-edge 和 n9e 之间网络断了,告警事件就写不到 mysql 了,但是只要 n9e-edge 所在机房的外网出口是好的,告警通知还是可以发出去的。
架构图中:
- 中心机房的 n9e 负责中心机房的 Loki、ElasticSearch 的告警判定,也负责机房 A 的 ElasticSearch 和 Prometheus 的告警判定
- 边缘机房 B 的 n9e-edge 负责机房 B 的 VictoriaMetrics 的告警判定
那如何指定不同的数据源和告警引擎之间的关联关系呢?其实是在数据源的管理页面:
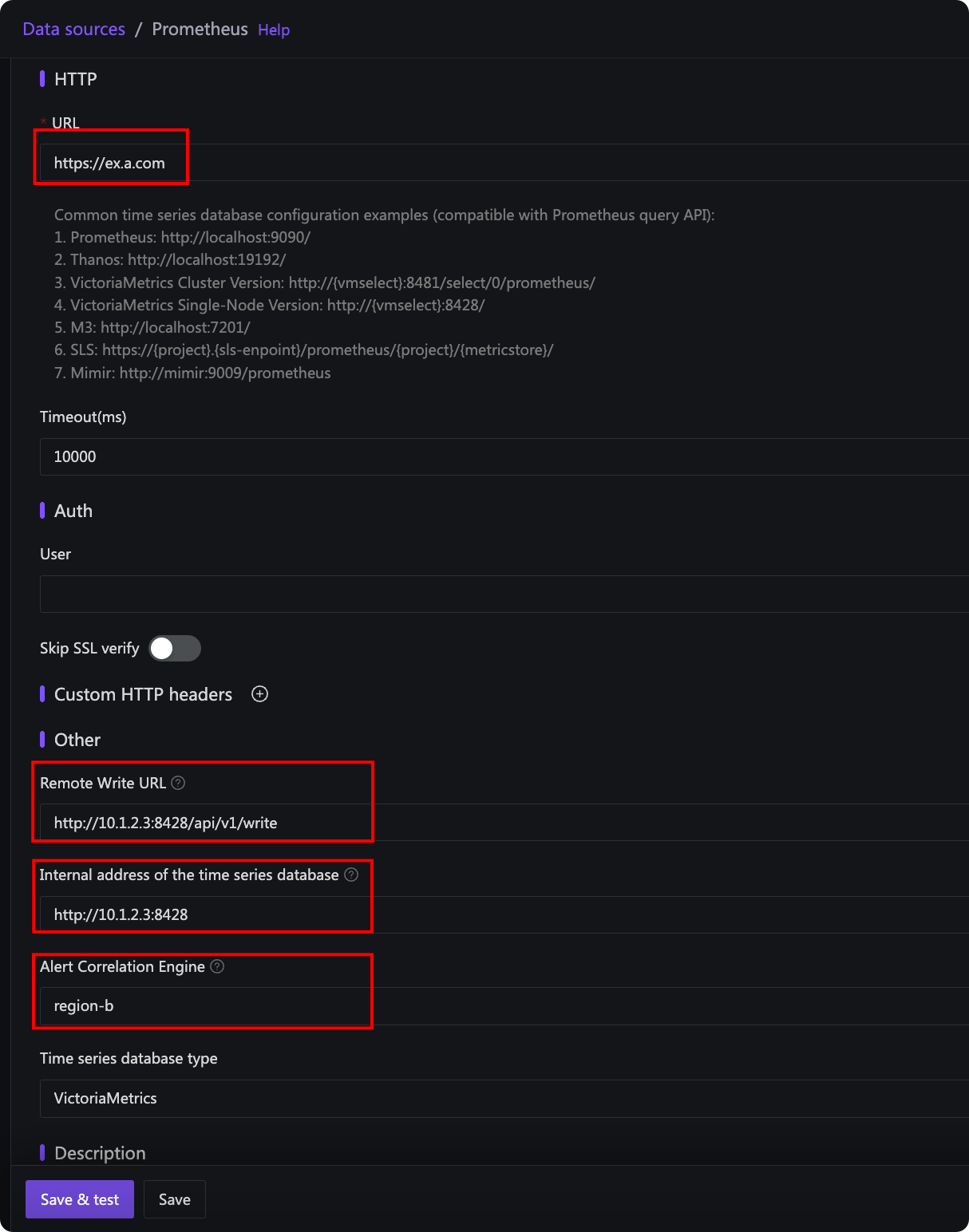
上图中:
- URL 是中心 n9e 读取数据的地址,在上例架构中,需要配置为 B 机房 VictoriaMetrics 的公网地址
- 时序库内网地址是 n9e-edge 连接 VictoriaMetrics 的地址,如果 URL 已经是一个内网地址了,这个配置项就可以留空,留空之后 n9e-edge 就会使用 URL 中的地址。上例中,由于 n9e-edge 和 VictoriaMetrics 在同一个机房,所以这个地址应该配置为内网地址,这样告警判定更可靠
- Remote Write URL 是 VictoriaMetrics 的 remote write 写入地址,用于记录规则,即 recording rule,n9e-edge 负责处理记录规则,把结果写回时序库,所以需要知道时序库的 remote write 地址,因为是给 n9e-edge 用的,所以使用内网地址。如果你没有用到夜莺的记录规则,这里可以不用配置
- 关联告警引擎集群,上图选择的是 edge-b,这是 B 机房 n9e-edge 的名字(由 edge.toml 的 EngineName 字段指定),这样配置之后,就建立了 B 机房 n9e-edge 和 B 机房 VictoriaMetrics 之间的关联关系,就会由这个 n9e-edge 来处理 B 机房 VictoriaMetrics 的告警规则和记录规则
新版本的夜莺,n9e-edge 依赖一个 redis,所以需要在 B 机房部署一个 redis 给 n9e-edge 使用,注意,n9e-edge 所用的 redis 和中心机房 n9e 所用的 redis 不是一个。架构图中我特意标注了 R1、R2 两个名字,表示两个 redis,分别给 n9e 和 n9e-edge 使用。
最后说一下 categraf,如果网络链路比较好,categraf 可以把数据直接上报到中心机房的 n9e,比如中心机房和 A 机房的 categraf 都可以直接对接到中心机房的 n9e,但是 B 机房部署了 n9e-edge,那 B 机房的 categraf 就应该对接到 B 机房的 n9e-edge。
配置样例
要达到上述架构,各个组件的配置文件应该如何配置?这里给出一个示例。
中心机房 n9e 配置
中心机房 n9e 的默认配置文件是 etc/config.toml:
[HTTP.APIForService]
Enable = true
[HTTP.APIForService.BasicAuth]
user001 = "ccc26da7b9aba533cbb263a36c07dcc5"
user002 = "ccc26da7b9aba533cbb263a36c07dcc6"
重点就是 HTTP.APIForService 这块的配置。默认 Enable 是 false 是为了安全考虑,即默认不支持 n9e-edge 架构,如果要支持,需要改成 true。n9e-edge 调用 n9e 的接口时,可以使用 BasicAuth 认证,即 HTTP.APIForService.BasicAuth 下面的部分,上例中配置了两个用户,分别是 user001 和 user002,密码是 ccc26da7b9aba533cbb263a36c07dcc5 和 ccc26da7b9aba533cbb263a36c07dcc6。其实配置一个用户就行,我配置两个只是为了演示。另外,如果你的 n9e 暴露在公网,千万要修改 BasicAuth 的默认密码,不然很容易被攻击。
边缘机房 n9e-edge 配置
边缘机房 n9e-edge 的默认配置文件是 etc/edge/edge.toml,首先 n9e-edge 要调用中心 n9e 的接口,所以要配置中心 n9e 的地址:
[CenterApi]
Addrs = ["http://N9E-CENTER-SERVER:17000"]
BasicAuthUser = "user001"
BasicAuthPass = "ccc26da7b9aba533cbb263a36c07dcc5"
# unit: ms
Timeout = 9000
N9E-CENTER-SERVER:17000 表示中心 n9e 的地址,你按照自己的环境调整即可。BasicAuthUser 和 BasicAuthPass 是中心 n9e 的 BasicAuth 用户名和密码,如果中心 n9e 没有开启 BasicAuth,这两个字段可以不填。还是那句话,千万要修改 BasicAuth 的默认密码,不然很容易被攻击。
新版本 n9e-edge 依赖 redis,所以要配置 redis 地址,默认应该是在 edge.toml 的最下面,自行修改即可。如果你是老版本,不依赖 redis,那就不用配置了。如何分辨你的版本的 n9e-edge 是否依赖 redis?就看你下载下来的 edge.toml 默认配置中是否带有 redis 配置,带了就说明依赖 redis。
边缘机房 categraf 配置
主要是注意 2 个地方,writer 的地址和 heartbeat 的地址,都配置为 n9e-edge 的地址:
...
[[writers]]
url = "http://N9E-EDGE:19000/prometheus/v1/write"
...
[heartbeat]
enable = true
# report os version cpu.util mem.util metadata
url = "http://N9E-EDGE:19000/v1/n9e/heartbeat"
...
N9E-EDGE:19000 表示 n9e-edge 的地址,注意,n9e-edge 默认监听的端口是 19000,也可以在 edge.toml 中自行修改。
ibex 配置
ibex 部分,即故障自愈的功能,这个功能有些公司担心安全问题不开放。如果你们要开启这个功能,同样的道理,在 edge.toml 中开启:
[Ibex]
Enable = true
RPCListen = "0.0.0.0:20090"
然后边缘机房的 categraf 连边缘机房的 n9e-edge 的 20090 端口即可,即 categraf 的 config.toml 要做如下配置:
[ibex]
enable = true
## ibex flush interval
interval = "1000ms"
## n9e ibex server rpc address
servers = ["N9E-EDGE-IP:20090"]
## temp script dir
meta_dir = "./meta"
N9E-EDGE-IP:20090 表示 n9e-edge 的 RPC 地址。注意这是 RPC 地址,不是 HTTP 地址,所以,不要在 N9E-EDGE-IP 前面画蛇添足加上 http:// 啦。
其他适用场景
除了网络链路不好的场景之外,有时为了安全考虑,网络也会有分区,比如某个网络区域只有一台中转机可以连通中心的 n9e,其他机器都不能连通,这时候就可以在中转机上部署 n9e-edge,然后其他机器的 categraf 连中转机的 n9e-edge 即可。