事件处理器 Pipeline
事件处理器(Event Processor)是夜莺 v8 版本引入的一个概念,当告警事件产生之后,在发送通知之前,可以使用事件处理器对告警事件做额外的处理,开源版本支持 Relabel、Callback、Event Update、Event Drop、AI Summary 5 类处理器,不同的处理器可以组成一个 Pipeline,对告警事件做一系列灵活的处理。场景比如:
- 跟内部的 CMDB 打通,附加一些更丰富的信息到告警事件上
- 调用 DeepSeek 的接口,对告警事件做一些智能分析,然后把分析结果附加到告警事件上
- 把所有告警事件发送到自己的系统,相当于镜像一份,做后续的分析处理
- 一些特定的告警事件可以 Drop 掉,比如一些恢复事件不想发送通知
这里涉及多个概念,通知规则、事件处理器(Processor)、事件处理管道(Pipeline),稍作解释:
- 一个通知规则里可以配置多个事件处理管道(Pipeline),顺序执行
- 一个事件处理管道(Pipeline)里可以配置多个事件处理器(Processor),也是顺序执行

上面的截图可以看出,入口菜单在 通知-通知规则,通知规则可能会有很多,在新增或编辑某个具体的通知规则时,可以看到有个 事件处理 的配置区域,这里可以引用多个提前创建好的事件管道(Pipeline),那在哪里对事件管道(Pipeline)增删改呢?入口比较隐藏,在 事件处理 右侧那个小齿轮里,点击可以展开一个侧拉板,在侧拉板里对事件管道(Pipeline)增删改。
创建、编辑事件管道(Pipeline)时,又会展开一个新的侧拉板,在这个新侧拉板里编辑 Pipeline,我们可以在 Pipeline 里配置多个事件处理器(Processor):

点击事件处理器类型字段旁边的 使用说明 可以查看事件处理器的使用说明文档。
Relabel 处理器
Relabel 处理器,类似 Prometheus 中对监控指标的 Relabel 操作,只不过夜莺这里,是对告警事件的 Relabel,告警事件里也有标签字段,也有需求对标签做一些加工处理,所以这里提供了 Relabel 处理器。
Relabel 处理器的具体使用说明,在夜莺的页面上点击事件处理器类型字段旁边的 使用说明,即可查看。
Callback 处理器
事件触发后,夜莺可以通过 Callback 通知外部系统,外部系统可以根据事件内容进行自动化处理。比如我见过有些公司自研了一套告警通知的系统,不用夜莺的通知机制,就直接把所有告警事件通过 Callback 处理器发送到自研的系统。
下面做一个简单的演示:
- 首先创建一个“通知规则”,因为 Callback 处理器属于某个 Pipeline,而 Pipeline 又属于某个通知规则。
- 在“通知规则”里,引用事件处理的 Pipeline,Pipeline 需要提前创建好(在通知规则编辑页面,点击处理器右侧的小齿轮打开侧拉板,在侧拉板里创建、编辑 Pipeline),下面截图是一个 Pipeline 的详情页面,里边有一个 Callback 处理器。
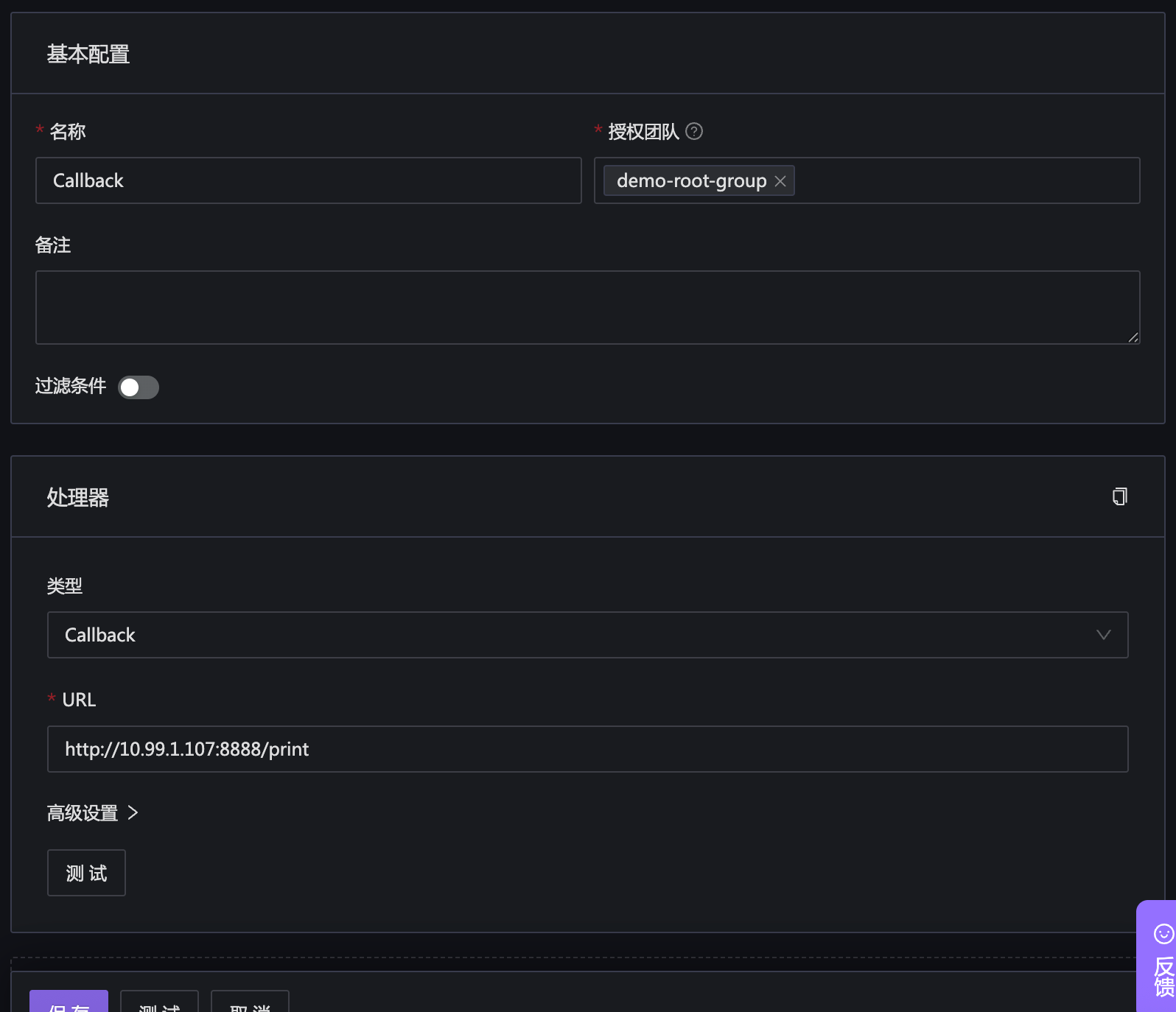
这里的
http://10.99.1.107:8888/print是我的一个测试程序,可以把接收到的 HTTP 请求打印出来,方便演示。这个程序也是一个开源小程序,地址在 github gohttpd。
创建了 Pipeline 之后,回到通知规则页面,在事件处理那里,选择刚才创建的 Pipeline。
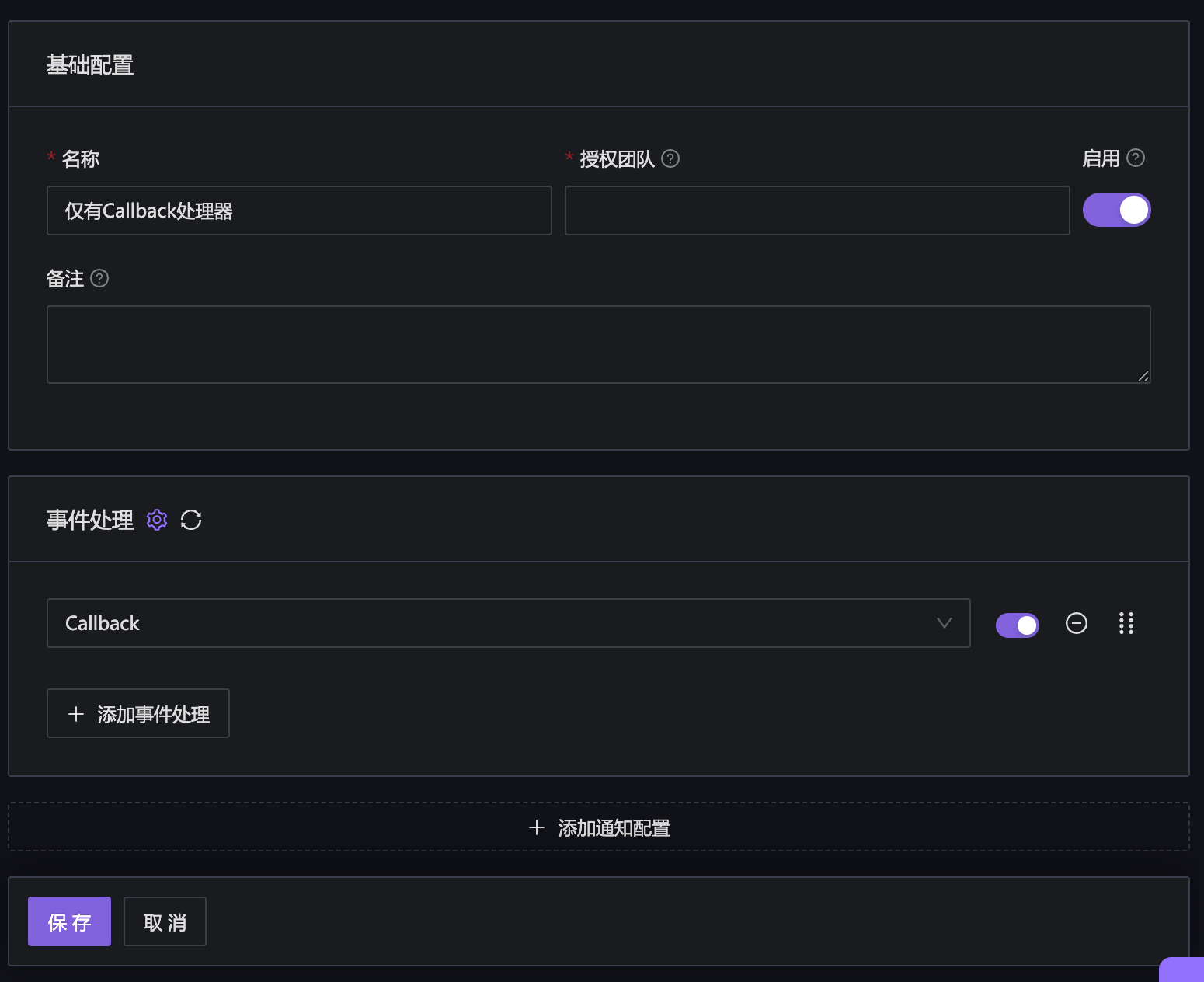
接下来,就可以去配置“告警规则”做测试了,测试一下产生的告警能否被第三方程序接收到。
为了尽快看到效果,可以创建一个肯定会触发阈值的告警规则,然后在通知规则那里,选择刚才创建的通知规则:
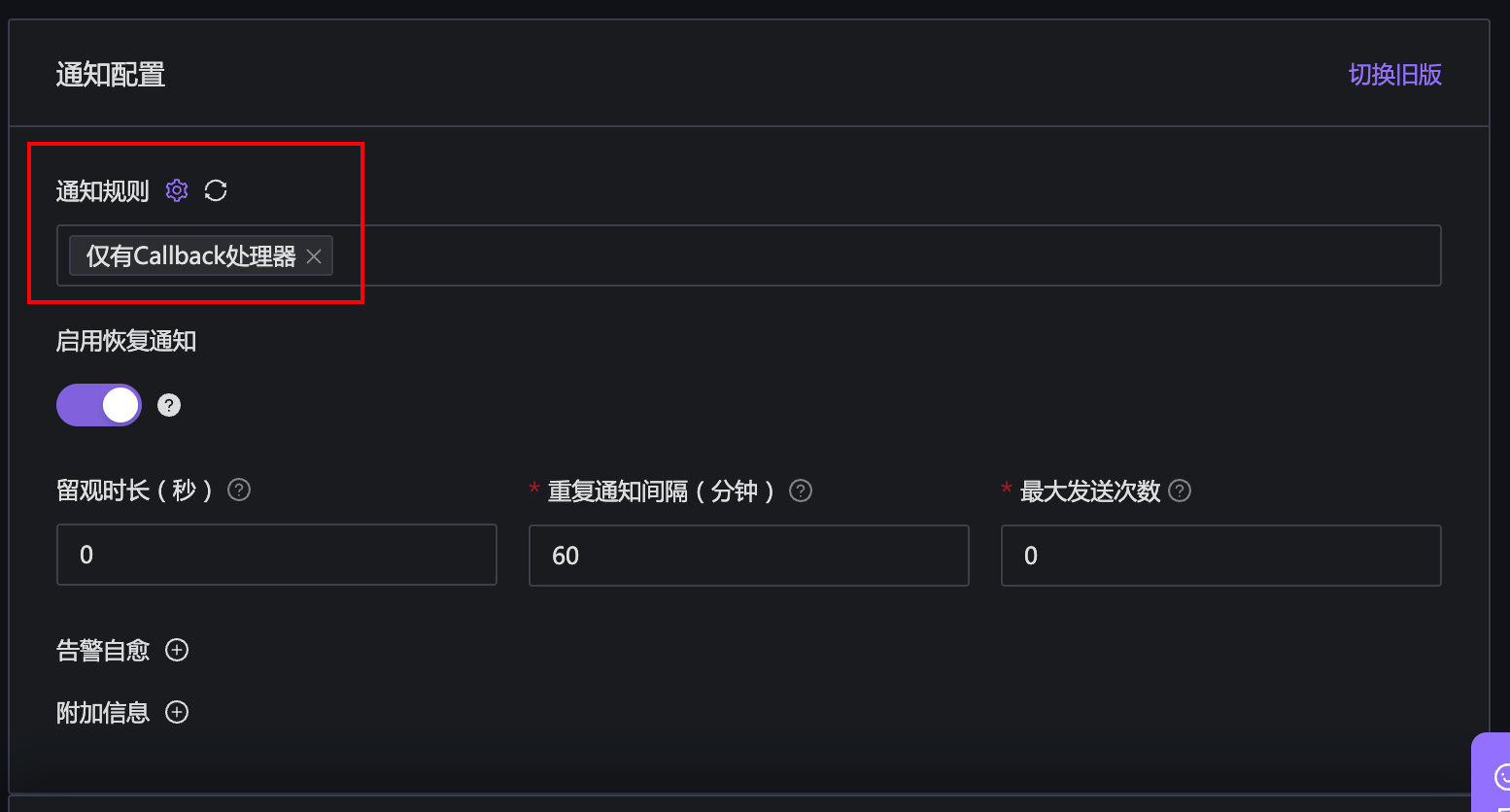
稍等片刻,去观察 http://10.99.1.107:8888/print 这个程序是否收到回调的 HTTP 请求。我的环境里看到的结果如下:

从上图可以看出,HTTP request 中包含了告警事件的信息,其内容如下:
{
"id": 1097371,
"cate": "prometheus",
"cluster": "prom",
"datasource_id": 1,
"group_id": 2,
"group_name": "DBA-Postgres",
"hash": "54f5543591c6dc0e30139cae196a1eee",
"rule_id": 54,
"rule_name": "测试事件回调",
"rule_note": "",
"rule_prod": "metric",
"rule_algo": "",
"severity": 2,
"prom_for_duration": 0,
"prom_ql": "cpu_usage_active{ident=\"ulric-flashcat.local\"} \u003e 0",
"rule_config": {
"queries": [{
"from": 0,
"prom_ql": "cpu_usage_active{ident=\"ulric-flashcat.local\"} \u003e 0",
"range": {
"display": "now-undefineds to now-undefineds",
"end": "now-undefineds",
"start": "now-undefineds"
},
"severity": 2,
"to": 0,
"unit": "none"
}]
},
"prom_eval_interval": 15,
"callbacks": [],
"runbook_url": "",
"notify_recovered": 1,
"target_ident": "ulric-flashcat.local",
"target_note": "",
"trigger_time": 1749180264,
"trigger_value": "33.06867",
"trigger_values": "",
"trigger_values_json": {
"values_with_unit": {
"v": {
"value": 33.06867479671808,
"unit": "",
"text": "33.07",
"stat": 33.06867479671808
}
}
},
"tags": ["__name__=cpu_usage_active", "cpu=cpu-total", "ident=ulric-flashcat.local", "rulename=测试事件回调"],
"tags_map": {
"__name__": "cpu_usage_active",
"cpu": "cpu-total",
"ident": "ulric-flashcat.local",
"rulename": "测试事件回调"
},
"original_tags": ["", "", "", ""],
"annotations": {},
"is_recovered": false,
"last_eval_time": 1749180264,
"last_sent_time": 1749180264,
"notify_cur_number": 1,
"first_trigger_time": 1749180264,
"extra_config": {
"enrich_queries": []
},
"status": 0,
"claimant": "",
"sub_rule_id": 0,
"extra_info": null,
"target": null,
"recover_config": {
"judge_type": 0,
"recover_exp": ""
},
"rule_hash": "dc128d86d65326499bd03ecfbe56e4c3",
"extra_info_map": null,
"notify_rule_ids": [3],
"notify_version": 0,
"notify_rules": null
}
测试正常。如果您有类似需求,就可以使用这种 Callback 处理器来对接,在您的程序中做一些自动化的逻辑。
Event Update 处理器
事件处理器中,还有一个 Event Update 处理器,和 Callback 的配置方式一样,这俩工作逻辑也很像,区别如下:
夜莺在调用 Callback 地址的时候,是不关注 HTTP Response 的,而在调用 Event Update 的时候,会把 HTTP Response 的内容作为新的告警事件走后续处理。
所以,Event Update 如其名,就是用来修改告警事件的。通常用于附加一些额外信息到告警事件中,比如:
- 把事件交给 AI 分析,得到一些结论性质的信息,附加到事件中
- 去 CMDB 查询一些元信息,附加到事件中
注意,告警事件的结构不能乱改,比如直接在 JSON 顶层增加一个字段,后续流程是不认的。通常建议把新内容附加到 annotations 字段,我上面 Callback 处理器的例子中,annotations 是空的所以看不出来数据结构,实际 annotations 是一个 map 结构,map key 和 map value 都是字符串类型,你要附加内容的时候,也需要遵循这个结构。
高级玩家也可以修改 Event 的其他字段,但是你得清楚你的修改对后续的影响,普通用户就只需要把内容附加到
annotations字段,然后把整个新的 Event 序列化为 JSON 放到 HTTP Response 的 body 中即可。
Event Drop 处理器
事件处理器中,还有一个 Event Drop 处理器,顾名思义,就是用来丢弃告警事件的。比如:
- 有些场景,虽然产生了告警事件,但是不想走后面的通知逻辑,就可以使用 Event Drop 处理器来丢弃这个事件。
要 Drop 掉一些告警事件,那肯定要做过滤,通常可以利用标签、注解、级别等各种字段做过滤,这个过滤规则可能会写的很复杂,那这个功能怎么设计才能如此灵活呢?我们想了一个稍微复杂但是极度灵活的办法,就是用户直接使用 go template 语法配置一段 template,template 中可以引用告警事件,使用 if 等语法来做过滤。只要这个 go template 最终渲染的结果是 true,就会丢弃这个事件。
具体使用说明,在夜莺的页面上点击 Event Drop 事件处理器类型字段旁边的 使用说明,即可查看。
AI Summary 处理器
AI Summary 处理器的文档也很齐全,如下图:
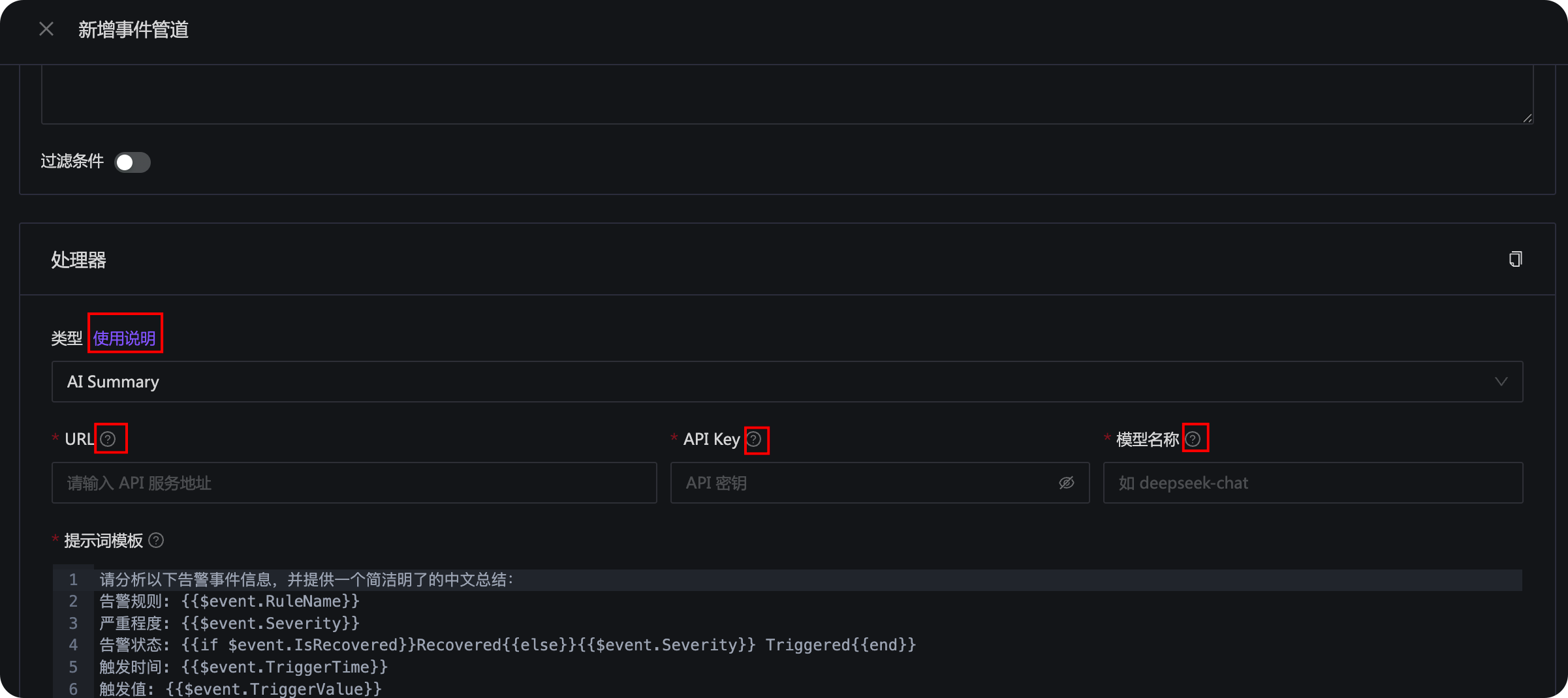
点击 AI Summary 事件处理器类型字段旁边的 使用说明,即可查看 AI Summary 处理器的使用说明文档。下面各个字段右侧都有一个小问号的 icon,鼠标挪上去也可以看到相关提示说明。